Cześć! Temat, który chciałbym dzisiaj wspólnie z Wami poruszyć, raczej nie posiada mocno ugruntowanej pozycji w świecie Pythona. Mam jednak wrażenie, że również na naszym podwórku w ostatnim czasie zanotowaliśmy wzrost zainteresowania kwestiami architektury. Trend ten bardzo mnie cieszy, gdyż uważam, że świadome myślenie o architekturze jest nieodłącznym elementem warsztatu profesjonalnego programisty.
Czym jest architektura?
Kiedy, jako poważni inżynierowie, zaczynamy rozmowę o architekturze oprogramowania, często możemy natrafić na pierwsze problemy już na początku – podczas próby skonstruowania jasnej definicji określającej, czym ta architektura właściwie jest. Poszukując informacji na ten temat, można natrafić na stwierdzenia typu:
Architektura oprogramowania dotyczy podejmowania fundamentalnych decyzji związanych ze strukturą naszego oprogramowania. Takich decyzji, które na późniejszym etapie (np. po implementacji) są trudne (kosztowne) do zmiany.
Definicja taka jest dość ogólna, aczkolwiek zawęża nasze postrzeganie decyzji związanych z architekturą, jako decyzji dotyczących struktury oprogramowania. Nie do końca może być jednak jasne czym ta struktura właściwie jest.
Nieco inne podejście zaproponował Ralph Johnson. Według współautora Design Patterns, jeżeli porozmawiamy z doświadczonymi członkami dobrze funkcjonującego zespołu projektowego, to okaże się, że posiadają oni pewną wspólną wiedzę, wspólne zrozumienie tego, jak zaprojektowany jest system. Współdzielą oni wyobrażenie jego struktury oraz informacje na temat tego, jak poszczególne komponenty współdziałają ze sobą, co jest od czego zależne. Ta współdzielona wiedza to właśnie architektura.
Martin Fowler odniósł się do powyższego podejścia i przedstawił konkretną ale i bardzo ogólną definicję. Skoro architektura to coś, czego zrozumienie jest współdzielone w zespole, zaś związane z nią decyzje trudno później zmienić to z pewnością dotyczą one „ważnych rzeczy”. Czymkolwiek by one nie były 😉 W ten sposób możemy postrzegać decyzje architektoniczne jako wszelkie ważne decyzje dotyczące tworzonego oprogramowania.
Analizując wypowiedzi i prezentacje ekspertów inżynierii oprogramowania, natrafimy na różne podejścia. Jednak, podobnie do opinii przytoczonych powyżej, większość z nich będzie mocno ogólna. Według mnie, trudność ujęcia tego konceptu w inny sposób, wynika z faktu, iż architektura sama w sobie jest pewnego rodzaju abstrakcją. A naszym mózgom trudno jest zrozumieć abstrakcję. Zazwyczaj w tym celu wspomagamy się odpowiednimi porównaniami. Oddają one pewne kluczowe dla nas cechy danej abstrakcji. Na przykład pojęcie takie jak czas. Trudno tutaj o bardzo konkretną a jednocześnie precyzyjną definicję. Nie przeszkadza to jednak nam w zrozumieniu jego działania. W tym celu, traktujemy czas jak inne obiekty, które potrafimy sobie wyobrazić. Czas to pieniądz – bo można go mieć, może się skończyć, płynie jak rzeka, itd.
Co łączy programowanie i remont mieszkania?
Aby dobrze zrozumieć, czym jest architektura oprogramowania, warto zasiągnąć przykładów pochodzących z branży budowlanej. W końcu to z niej “podkradliśmy” to pojęcie. Jeżeli pomyślimy na chwilę o mieszkaniu: naszym, naszych znajomych, rodziców – to z pewnością dostrzeżemy, że różnią się one między sobą. Znawca wnętrz z pewnością byłby w stanie sklasyfikować każde z nich i przypisać mu konkretny styl: loft, skandynawskie, modernistyczne, itd. Każde mieszkanie posiada jakiś styl.

Czasami klasyfikacja może być trudna, ale nie zmienia to faktu, że mieszkanie posiada pewien (być może mieszany) styl. Podobnie ma się sprawa z architekturą oprogramowania. Oprogramowanie zawsze jest wykonane w jakimś stylu. Styl ten, może nie być taki, jaki by się nam marzył ale ostatecznie jakiś jest. Tak jak w branży wykończeń, istnieją konkretne, zdefiniowane style, tak samo oprogramowaniu możemy przypisywać różne style architektoniczne. W obu przypadkach, trudno jest też wyznaczyć bardzo wyraźne granice. Nie można stwierdzić, ile dokładnie błyszczących mebli trzeba dokupić, żeby zmienić styl z klasycznego na glamour. Nie jest to jednak przeszkodą w projektowaniu ładnych mieszkań – oraz systemów 😉 .
Powyższe przemyślenia prowadzą nas przynajmniej do trzech powodów, dla których warto poświęcić architekturze oprogramowania dodatkową porcję uwagi:
- Architektura jest nieunikniona – każda aplikacja, każdy system ma jakąś. Może ona jednak nie być taka, jaką sobie wymarzyliśmy
- Są różne style architektoniczne – mamy z czego wybierać, warto więc dokonać tego wyboru świadomie
- Decyzje architektoniczne dotyczą “ważnych rzeczy” 😉
Dobra architektura
Idąc krok dalej, zastanówmy się czym jest dobra architektura. Okazuje się, że odpowiedź na to pytanie jest zdecydowanie prostsza niż stwierdzenie czym jest architektura w ogóle. Odnosząc się do przykładu: w jaki sposób stwierdzić, że filiżanka ze zdjęcia poniżej jest dobrze zaprojektowana?

Dlaczego jest taka a nie inna? Najpewniej osoby, które decydowały o tym projekcie, brały pod uwagę różne czynniki związane z jej przeznaczeniem:
- Ile kawy zazwyczaj pije osoba dorosła
- Do jakiego sposobu trzymania filiżanki jesteśmy przyzwyczajeni
- Jakie są oczekiwania dotyczące estetyki
- Ile może kosztować jedna sztuka
W tym kontekście podejmowane były decyzje i w tym samym kontekście należy je oceniać. Tak więc filiżanka (ale i oprogramowanie) jest dobrze zaprojektowana jeżeli spełnia postawione przed nią cele. Jeżeli została stworzona dla osób dorosłych, do picia kawy w kawiarni lub zaciszu domowym, to najpewniej ocenimy ją pozytywnie. Jednak ten sam projekt, przedstawiony jako rozwiązanie dla małych dzieci, z pewnością przegra rywalizację z kubkiem-niekapkiem.
Drivery architektoniczne
Projektując oprogramowanie, tak samo jak twórcy porcelany, powinniśmy kierować się postawionymi przed nami celami. W podjęciu decyzji pomocne jest zastosowanie analizy tzw. driverów architektonicznych – czyli wymagań kierujących nasz projekt w odpowiednim kierunku. Możemy je sklasyfikować jako:
- Oczekiwana funkcjonalność
- Wymagania jakościowe
- Ograniczenia
- Konwencje i zasady
Oczekiwana funkcjonalność
W tej kategorii znajdują się wszystkie wymagania funkcjonalne czyli to “co” system ma robić. Zapisywać zgłoszenia, wysyłać powiadomienia, umożliwiać płatności, generować raporty. Tym wymaganiom poświęcamy zazwyczaj sporo uwagi, często doczekują się one również konkretnej, udokumentowanej formy – w postaci różnego rodzaju User Stories czy scenariuszy biznesowych. Rozmowa na ich temat jest oczywista i często to właśnie przez pryzmat dostarczanej funkcjonalności postrzegamy nasz system.
Wymagania jakościowe
Czyli skalowalność, dostępność, niezawodność, testowalność, rozwijalność itd. Poszukując driverów architektonicznych z tego obszaru, powinniśmy zwrócić uwagę na wszystkie parametry jakościowe ważne z punktu widzenia celów biznesowych. Czy dany komponent musi działać absolutnie niezawodnie? Czy przez jaki czas może być niedostępny? Czy musi dać się go skalować?
Zbieranie tego rodzaju oczekiwań, może być utrudnione z kilku powodów.
Po pierwsze, często mogą zostać one niejawnie zaszyte w wymaganiach funkcjonalnych. Klient opowiadając o konkretnej funkcjonalności zazwyczaj ma pewne (niekoniecznie bardzo skonkretyzowane) wyobrażenie dotyczące również jej atrybutów jakościowych. Przykładowo, mówiąc o usłudze powiadomień mailowych o nowo zarejestrowanych użytkownikach platformy, oczekuje jej niezawodności na pewnym poziomie. Jeżeli na platformie zarejestruje się 100 użytkowników, a dotrze jedynie 50 maili z powiadomieniem, to w perspektywie klienta, ta funkcjonalność po prostu nie działa. Jednak ten sam klient może nie widzieć żadnego problemu w tym, że na 100 rejestracji zagubi się pojedyncza wiadomość. Analogicznie sprawa ma się z innymi wymaganiami funkcjonalnymi i wiążącymi się z nimi oczekiwaniami jakościowymi.
Po drugie, zadanie udziałowcom biznesowy trzech wymienionych wcześniej pytań wprost, może doprowadzić nas do następujących odpowiedzi:
- Tak, musi działać absolutnie niezawodnie.
- Musi być dostępny przez 100% czasu
- Tak, musi być skalowalny
PS: to przecież oczywiste, dlaczego w ogóle o to pytacie?
Jednak spełnienie tego typu wymagań często jest bardzo trudne (a tym samym czaso i kosztochłonne), a nawet niemożliwe. W wielu sytuacjach jest również zupełnie nie potrzebne. Bo drążąc temat możemy dowiedzieć się, że:
- Niezawodność
A: Czy jeżeli zdarzyłoby się, że spośród 500 wysłanych wiadomości 1 nie doszłaby do celu, to spowoduje duży problem?
B: 1 powiadomienie? Nie, to żaden problem. I tak zobaczę tego użytkownika logując się do panelu administracyjnego, prawda? - Dostępność
A: Czy gdyby zdarzyła się poważna awaria to moglibyśmy udostępnić raporty z jednodniowym opóźnieniem?
B: Jasne, i tak zawsze analizujemy dane z poprzedniego tygodnia, praktycznie nigdy z bieżącego - Skalowalność
A: Ile użytkowników będzie korzystało z tego systemu?
B: W tym roku najpewniej testowo 5 osób. W przyszłym planujemy zaangażować całą firmę, 40 osób
Trzecie wyzwanie stanowi definicja atrybutów jakościowych. Samo stwierdzenie, że system ma być „dostępny” nie daje nam jeszcze zbyt dużo informacji. W związku z tym, dobrą praktyką jest próba powiązania z atrybutem jakościowym odpowiadającej nam metryki i ustalenia dla niej oczekiwanych wartości. Przykładowo:
Dla komponentu X przerwa w działaniu, w czasie godzin biznesowych (PN-PT, 6:00-18:00) nie może wynieść więcej niż 2 godziny w miesiącu.
Dla niektórych atrybutów ustalenie metryk może być trudne i czasami wymagać pomiaru kilku oczekiwanych charakterystyk (np. dla testowalności szybkości wykonania testów i poziomu pokrycia logiki biznesowej).
Ograniczenia
Przykładem ograniczeń występujących praktycznie w każdym projekcie są:
- Czas na realizację
- Dostępne fundusze
- Liczność zespołu
- Dostępność konkretnych kompetencji w zespole i poziom wiedzy poszczególnych osób z załogi
Ich określenie narzuca bardzo konkretne ramy działania i w teorii nie powinno być trudne. Niestety w praktyce zdarza się, że podawany czas na realizację projektu jest celowo mocno zaniżony (bo biznes “dorzucił” sobie bardzo konkretne bufory, mnożąc czas przedstawiony jako nieprzekraczalne wymaganie zespołowi przez 4). Tego typu sytuacja może doprowadzić do wybrania nieoptymalnej architektury i uniemożliwić spełnienie innych ważnych oczekiwań stawianych oprogramowaniu. Taka sytuacja ma zazwyczaj związek z niską świadomością konsekwencji i brakiem zaufania do zespołu (lub całej branży, często z powodu negatywnych doświadczeń z przeszłości). Dlatego tak ważna jest transparentna komunikacja, profesjonalne podejście i próba dotarcia do rzeczywistych potrzeb biznesu.
Konwencje i zasady
Jeżeli pracujemy w Pythonowym Softwarehous’ie to najpewniej nie będziemy implementować backendu w C#. Nawet jeżeli w naszym zespole znalazłby się komplet programistów znających tę technologię. Wynika to z zasad panujących w danej organizacji. W tym przypadku motywacją tych zasad mogą być kwestie braku osób do późniejszego rozwoju systemu, niezgodność ze strategią marketingową firmy itd. Innym przykładem konwencji jest konkretny sposób nazewnictwa albo stosowanie danego typu narzędzi (np. w związku z posiadanym partnerem, realizującym nisko kosztowe wsparcie). Często różne konwencje są dla nas tak oczywiste, że nawet nie dostrzegamy ich istnienia i automatycznie podejmujemy zgodne z nimi decyzje projektowe. Warto jednak upewnić się, czy dobrze rozumiemy je w kontekście konkretnego projektu oraz czy jakaś “oczywistość” nie umknęła nam w komunikacji z klientem (nie będziecie używać Oracle’a? Jak nasz zespół ma przejąć od Was utrzymanie tego systemu? 😉 )
Architektura na różnych poziomach
Wyposażeni w zestaw driverów pozwalających nam dobrze projektować nasze oprogramowanie zmierzamy do określenia zbioru dostępnych możliwości. Co ważne, możliwości te są różne, na różnych poziomach.
Jak to poziomach? Otóż tak jak na budynek możemy patrzeć analizując każde znajdujące się w nim mieszkanie albo też traktując jego bryłę jako jedną całość, tak samo architekturę oprogramowania możemy postrzegać z punktu widzenia całego systemu albo pojedynczej aplikacji (modułu). Na każdym z tych poziomów wyróżniamy odrębne style architektoniczne.
Przykłady styli architektury systemowej:
- System monolityczny – brak fizycznego i logicznego rozproszenia, często postrzegany jako jedna wielka kula spaghetti (albo błotka 😉 )
- Modularny system monolityczny – jego komponenty nie są rozproszone fizycznie jednak w ramach całego systemu zostały wyodrębnione stosunkowo niezależne, logiczne moduły
- Architektury oparte o szynę danych (Enterprise Service Bus)
- Systemy rozproszone – wariantem tego rodzaju architektury są mikroserwisy, gdzie nieduże logiczne moduły są również rozproszone fizycznie pomiędzy wiele usług
Przykłady styli architektury aplikacyjnej:
- Architektura warstwowa (np. 3-warstwowa: prezentacja/logika/dane)
- Hexagonal/Clean architecture
- Pipe and filters
- Architektura pluginowa
- Mixin (Magic) Driven
Dokładne omówienie poszczególnych styli zdecydowanie wykracza poza temat jednego artykułu. Jednak, żeby połączyć przedstawione wcześniej koncepcje z konkretnym Pythonowym kodem, omówimy przykład porównujący zastosowanie Mixin (Magic) Driven Architecture z Hexagonal/Clean Architecture. Pierwsza architektura niejako narzuca nam zastosowanie anemicznego modelu rozwiązania, zaś w drugiej bardzo dobrze sprawdza się model bogaty. W celu ograniczenia nieco objętości tego artykułu opiszę w nim tylko podstawowe koncepty bez szczegółowego wyjaśniania poszczególnych building blocków, założeń i możliwości każdego stylu architektonicznego. Dokładnym omówieniem poszczególnych styli architektonicznych zajmiemy się w osobnych postach 🙂
Chwila, chwila! Ale o jakim modelu anemicznym my tu przed chwilą mówiliśmy? Model bogaty? I co to jest Mixin Driven Architecture?!
Mixin Driven Architecture
Tak więc po kolei. Nazwa Mixin Driven Architecture nie jest żadnym oficjalnym, czy nawet popularnym konceptem. W ten sposób, z przymróżeniem oka, nazywam podejście, które możemy uzyskać np. stosując Django z DRFem i opierając konstrukcję naszej aplikacji o zestawy dostarczonych przez framework mixinów. W systemie takim dużo rzeczy dzieje się automatycznie (automagicznie) stąd też “Magic”. Nie uważam, że podejście tego typu jest kategorycznie złe. Jak każde, ma ono swoje plusy i minusy. Świetnie się sprawdza w pewnych okolicznościach, gorzej w innych.
Modele
Kolejny temat to różnice pomiędzy modelem anemicznym a bogatym. Model to pewna niedoskonała reprezentacja (czegoś). Np. papierowa mapa jest modelem Ziemi. Istnieją różne warianty mapy, odwzorowujące zgodnie z oryginałem pola powierzchni kontynentów czy też odległości pomiędzy punktami. W zależności od celu, do jakiego chcemy wykorzystać mapę, możemy stosować różne jej warianty. W kontekście modelu anemicznego i bogatego mówimy o modelowaniu rozwiązania postawionego problemu biznesowego. Przykładowo, jeżeli naszym rozwiązaniem jest: umożliwienie wstrzymania okresu ubezpieczeniowego dla klientów ubezpieczalni pojazdów “na godziny” to możemy zamodelować nasze rozwiązanie na różne sposoby.
Model anemiczny
W tym podejściu postrzegamy rozwiązanie jako serie operacji na danych, które wyciągamy z obiektów zarządzanych przez ORM. Tak więc, po znalezieniu naszego ubezpieczenia “wyciągamy” z niego potrzebne nam dane. Następnie ustawiamy co potrzeba i ciach “save” na całości.
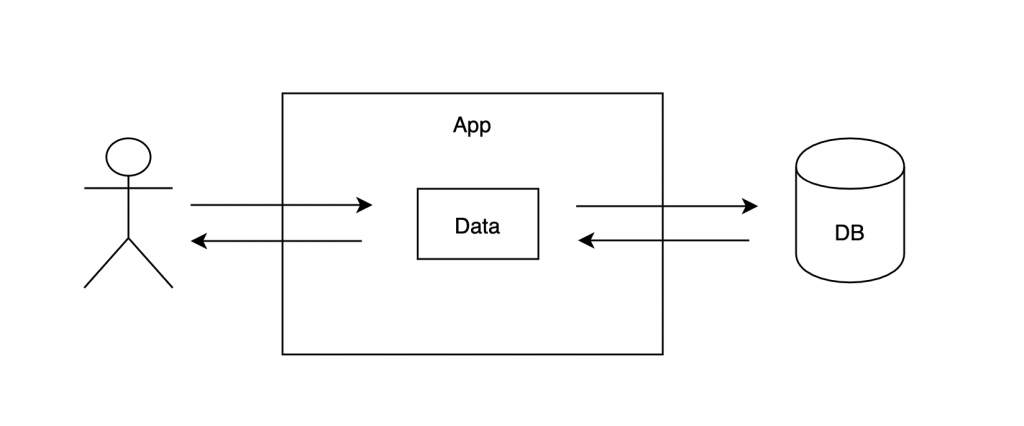
Podejście takie, w połączeniu ze wspomnianym wcześniej Django i DRF sprawdza się bardzo dobrze przy rozwiązywaniu problemów typu CRUD. Na przykład, kiedy musimy udostępnić proste CRUDowe API do zarządzania dostępnym katalogiem produktów. Stosując Django z DRFem otrzymujemy prosty, deklaratywny kod, który realizuje oczekiwane zadanie w zaledwie kilkunastu linijkach!
class Product(models.Model):
description = models.TextField()
image = models.ImageField()
category_description = models.TextField()
price = models.IntegerField()
activated = models.BooleanField()
class ProductSerializer(serializers.ModelSerializer):
class Meta:
model = Product
fields = "__all__"
class ProductViewSet(serializers.ModelSerializer):
queryset = Product.objects.all()
serializer_class = ProductSerializerSprawy mają się gorzej, jeżeli implementowany moduł zawiera sporo relatywnie skomplikowanych warunków biznesowych. Wyobraźmy sobie kontekst, w którym:
Budujemy system dla ubezpieczalni samochodów “na godziny”. Kierowcy używają aplikacji mobilnej do wstrzymywania oraz wznawiania ochrony. System musi przechowywać informacje na temat ubezpieczenia, jego aktualnego statusu, śledzić zmiany, czas obowiązywania subskrypcji ubezpieczeniowej itp. Musimy zapisywać historię wstrzymywania ubezpieczenia (od kiedy – do kiedy). Biznes chciałby również móc rozróżnić następujące stany ubezpieczenia:
- Aktywne (nie zostało wstrzymane i czas ochrony jeszcze nie minął)
- Wstrzymane (zostało wstrzymane, brak ochrony w tym czasie)
- Okres przejściowy (tzw. Grey Period, czas na odnowienie ubezpieczenia, rozwiązanie problemów z kartą płatniczą, itp.)
- Nieaktywne (czas ubezpieczenia oraz Okres Przejściowy minął)
Scenariusze użycia:
- Kierowca wstrzymuje ubezpieczenie kiedy nie pracuje
- Nie można wstrzymać ubezpieczenia gdy osiągnięto limit pauz
- Nie można wstrzymać, gdy już jest wstrzymane
- Nie można wstrzymać, gdy jest nieaktywne
- Kierowca wznawia ubezpieczenie, gdy jest z powrotem w pracy
- Nie można wznowić, gdy nie jest wstrzymane
- Nie można wznowić, jeżeli samochód znajduje się poza dopuszczoną strefą
Modelując rozwiązanie zgodnie z podejściem anemicznym i wykorzystując dostępne mixiny, można przedstawić je w następujący sposób:
1. Tworzymy nową pauzę
2. Aktualizujemy pauzę ustawiając czas jej zakończenia
Implementując prosty model Ubezpieczenia i związanych z nim Pauz, możemy wykorzystać ModelViewSet, prosty serializer i “ograć” podstawową wersję scenariusza pierwszego w kilku linijkach:
class PauseViewSet(ModelViewSet):
queryset = Pause.objects.all()
serializer_class = PauseSerializer
class PauseSerializer(serializers.ModelSerializer):
class Meta:
model = Pause
fields = "__all__"Żeby zapewnić ustawienie czasu rozpoczęcia i zakończenia pauzy możemy nadpisać domyślne implementacje create i update w serializerze:
def create(self, validated_data):
validated_data["begin_at"] = now
validated_data["end_at"] = None
return super().create(validated_data)
def update(self, instance, validated_data):
validated_data["begin_at"] = instance.begin_at
validated_data["end_at"] = now
return super().update(instance, validated_data)Jeżeli uznamy reguły opisane w wymaganiach za rodzaj walidacji, to może okazać się, że trafią one wszystkie do metody validate serializera:
def validate(self, attrs):
insurance = Insurance.objects.get(identifier=attrs["insurance_identifier"])
if self.instance:
if insurance.status is not Insurance.Status.ON_HOLD:
raise ValidationError()
location = current_location(insurance.car_id)
if not(50 < location.latitude < 55 and 15 < location.longitude < 25):
raise ValidationError()
else:
if len(insurance.pauses) >= MAX_AVAILABLE_PAUSES:
raise ValidationError()
if insurance.status is Insurance.Status.ON_HOLD:
raise ValidationError()
if insurance.status is Insurance.Status.INACTIVE:
raise ValidationError()
return attrsTeraz powinniśmy poradzić sobie jeszcze z aktualizacją stanu ubezpieczenia. Dokładając to wymaganie do create/update mamy:
insurance = Insurance.objects.get(identifier=validated_data["insurance_identifier"])
insurance.status = Insurance.Status.ACTIVE
insurance.save()oraz
insurance = Insurance.objects.get(identifier=validated_data["insurance_identifier"])
insurance.status = Insurance.Status.ON_HOLD
insurance.save()Rozwiązanie działa i wydaje się być z grubsza poprawne. POST na nasz endpoint tworzy pauzę (wstrzymuje ubezpieczenie), PUT aktualizuje pauzę (wznawia ubezpieczenie). Może nie do końca RESTful ale… Kodu nie za dużo powstało – dobra nasza! Pewnie jakieś testy jeszcze by się przydały… Tutaj trochę gorzej sprawa wygląda. Cokolwiek napiszemy będzie wymagało bazy danych, jakiś fixtur z modelami… Ewentualnie można to jeszcze testowym klientem zaatakować… No i w sumie nie do końca dobrze obsługujemy wznawianie ubezpieczenia – bo przecież możemy wznawiać będąc już w statusie GREY_PERIOD – kolejny if będzie… O nie – jeszcze nie skończyliśmy testów pisać, a klient już jakieś zmiany wprowadza!
Pojawiło się nowe wymaganie:
Kierowca może pauzować ubezpieczenie: Niezależnie jak wiele razy ubezpieczenie było wcześniej wstrzymywane kierowca może zatrzymać ochronę używając pauzy na “sztywny” okres czasu, bez możliwości wznowienia. Kierowcy będą korzystać z tej możliwości jeżeli przerwą pracę na dłuższy czas i nie będą mieli już dostępnego limitu wstrzymań. Taka pauza zostanie automatycznie zakończona, a ubezpieczenie wznowione po upływie ustalonego okresu. Z tej pauzy nie wolno korzystać w Okresie Przejściowym. Czas trwania pauzy to 1 dzień, chyba że do rozpoczęcia Okresu Przejściowego zostało mniej. Pauza ta wlicza się do ogólnej liczby użytych pauz (mimo, że nie wymaga posiadania limitu do jej użycia).
Jak to pauzować?! Przecież już tworzymy pauzy. No tak – ale tamto to niby było “wstrzymanie”. No cóż – na froncie przyślą nam dodatkowy parametr, np. ‘pause’ i po tym poznamy czy ma to być zwykła pauza czy specjalna:
class PauseSerializer(serializers.ModelSerializer):
pause = serializers.BooleanField()
...
def create(self, validated_data):
if validated_data.get("pause"):
...Powyższe rozwiązanie może występować w różnych odmianach. Część lub cała logika może zostać umieszczona bezpośrednio w widoku, ewentualnie funkcjach “helperach”. We wszystkich tych przypadkach modelujemy bardziej skomplikowane reguły biznesowe jako manipulacje bezpośrednio na danych, swobodnie wyciąganych i wkładanych do obiektów. Jednocześnie bardzo mocno wiążemy się z frameworkiem. Podejście to będzie cechować się:
- Szybko rosnącym stopniem zagmatwania, rozdrobnienia logiki biznesowej i spadkiem czytelności kodu
- Niską testowalnością (dużo mocków, trudne do napisania i wolne testy – potrzebna baza danych, testowy klient)
Po bardzo szybkim starcie dopasowanie kolejnych wymagań biznesowych i zmieniających się reguł do przyjętego przez nas modelu rozwiązania staje się coraz trudniejsze i wymaga coraz to bardziej skomplikowanych tricków.
Model bogaty
Alternatywnym podejściem do tematu może być zastosowanie modelu bogatego oraz architektury wspierającej testowalność i rozdzielenie skomplikowanej logiki biznesowej od szczegółów technicznych.
Budując model bogaty, postrzegamy nasze rozwiązanie jako serię interakcji z obiektami posiadającymi pewne zachowania i ukrywającymi przed światem ich szczegóły. Tak więc ogólne kroki algorytmu to: zainicjowanie obiektu domenowego, interakcja z obiektem (zachowania), zapis reprezentacji danych do bazy.
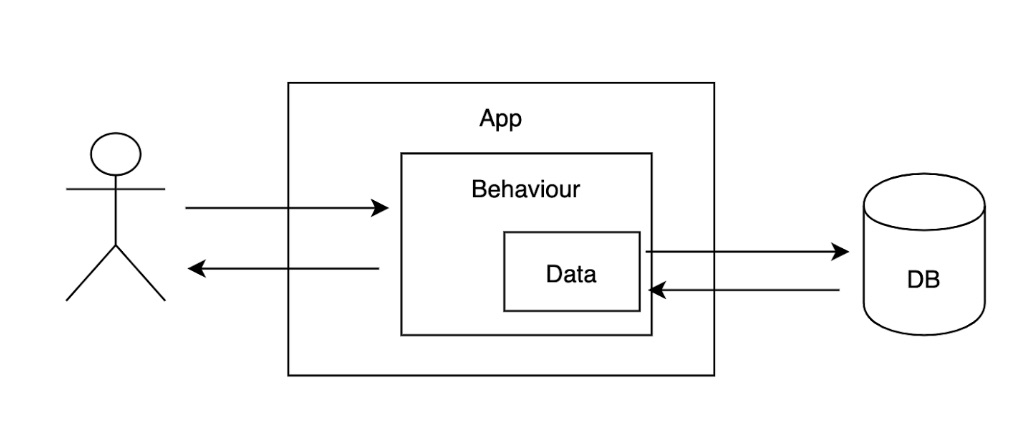
Spróbujmy zatem zamodelować powyższy przykład w ten sposób. Zacznijmy od modelu domenowego, reprezentującego opisywane przez wymagania zachowania:
class InsuranceStatus(Enum):
ACTIVE = auto()
ON_HOLD = auto()
IN_GREY_PERIOD = auto()
INACTIVE = auto()
@dataclass
class Pause:
insurance_identifier: str
begin_at: Datetime
end_at: Optional[Datetime] = None
@dataclass
class Insurance:
identifier: str
car_id: str
protection_end: Datetime
status: InsuranceStatus
pauses: List[Pause] = field(default_factory=list)
def hold(self):
...
def resume(self, current_location: Location):
...Mamy ogólny interfejs, teraz czas na testy! Zapisując 1:1 reguły biznesowe otrzymamy przejrzysty i ekspresowo działający zestaw testów. Jedyne fixtury, których potrzebujemy to proste obiekty z danymi, bez zależności od bazy danych.
def test_hold_insurance(insurance):
insurance.hold()
assert insurance.status is InsuranceStatus.ON_HOLD
def test_unable_to_hold_when_exceeded_pause_limit(insurance, allowed_location):
for _ in range(MAX_AVAILABLE_PAUSES):
insurance.hold()
insurance.resume(allowed_location)
with pytest.raises(PauseLimitExceeded):
insurance.hold()
def test_unable_to_hold_when_already_on_hold(insurance):
insurance.hold()
with pytest.raises(UnableToHoldOnHold):
insurance.hold()
def test_unable_to_hold_when_in_inactive_status(insurance):
insurance.status = InsuranceStatus.INACTIVE
with pytest.raises(UnableToHoldInactive):
insurance.hold()
def test_resume_insurance(insurance, allowed_location):
insurance.hold()
insurance.resume(allowed_location)
assert insurance.status is InsuranceStatus.ACTIVE
def test_unable_to_resume_when_not_on_hold(insurance, allowed_location):
with pytest.raises(WrongStateForAction):
insurance.resume(allowed_location)
def test_unable_to_resume_when_outside_the_allowed_location(insurance, not_allowed_location):
insurance.hold()
with pytest.raises(CarLocationNotAllowed):
insurance.resume(not_allowed_location)Następnie implementujemy konkretne metody:
@dataclass
class Pause:
insurance_identifier: str
begin_at: Datetime
end_at: Optional[Datetime] = None
def finish(self):
if self.end_at:
raise PauseAlreadyFinished()
self.end_at = now
@dataclass
class Insurance:
identifier: str
car_id: str
protection_end: Datetime
status: InsuranceStatus
pauses: List[Pause] = field(default_factory=list)
def hold(self):
if len(self.pauses) >= MAX_AVAILABLE_PAUSES:
raise PauseLimitExceeded()
if self.status is InsuranceStatus.ON_HOLD:
raise UnableToHoldOnHold()
if self.status is InsuranceStatus.INACTIVE:
raise UnableToHoldInactive()
self.pauses.append(Pause(insurance_identifier=self.identifier, begin_at=now))
self.status = InsuranceStatus.ON_HOLD
def resume(self, current_location: Location):
if self.status is not InsuranceStatus.ON_HOLD:
raise WrongStateForAction()
if not self._is_location_allowed(current_location):
raise CarLocationNotAllowed()
last_pause = self.pauses[-1]
last_pause.finish()
self.status = self._subscription_status()
def _is_location_allowed(self, location: Location) -> bool:
return 50 < location.latitude < 55 and 15 < location.longitude < 25
def _subscription_status(self):
if now <= self.protection_end:
return InsuranceStatus.ACTIVE
if self.protection_end < now <= self.protection_end + GREY_PERIOD_TIME:
return InsuranceStatus.IN_GREY_PERIOD
return InsuranceStatus.INACTIVE
def __eq__(self, other):
if not isinstance(other, Insurance):
return False
return other.identifier == self.identifierW tym kontekście dodanie nowego wymagania dotyczącego pauzowania ubezpieczenia nie jest nadzwyczaj trudne:
def pause(self):
...Łatwo i przyjemnie implementujemy kolejny pakiet testów jednostkowych:
def test_pause_for_constant_period_when_exceeded_pause_limit(insurance, allowed_location):
for _ in range(MAX_AVAILABLE_PAUSES):
insurance.hold()
insurance.resume(allowed_location)
insurance.pause()
assert insurance.status is InsuranceStatus.ON_HOLD
def test_unable_to_resume_pause(insurance, allowed_location):
insurance.pause()
with pytest.raises(PauseAlreadyFinished):
insurance.resume(allowed_location)
def test_unable_to_pause_when_in_grey_period(insurance):
insurance.status = InsuranceStatus.IN_GREY_PERIOD
with pytest.raises(WrongStateForAction):
insurance.pause()
def test_pause_not_overlap_on_grey_period(insurance, after_10_min):
insurance.protection_end = after_10_min
insurance.pause()
assert insurance.pauses[-1].end_at == after_10_minOraz logikę:
def pause(self):
if self.status is not InsuranceStatus.ACTIVE:
raise WrongStateForAction()
pause_end = now + PAUSE_TIME
if pause_end > self.protection_end:
pause_end = self.protection_end
self.pauses.append(Pause(insurance_identifier=self.identifier, begin_at=now, end_at=pause_end))
self.status = InsuranceStatus.ON_HOLDBiorąc pod uwagę modele ORMowe, które musieliśmy stworzyć dla przykładu anemicznego, na moment obecny napisaliśmy podobną ilość kodu, aczkolwiek nie rozmawiamy jeszcze z bazą danych ani nie udostępniamy API. Aby temu zaradzić musimy:
- Zaimplementować repozytorium i zdefiniować tabele bazodanowe
- Zaimplementować serwis aplikacyjny, który połączy nasz model domenowy z infrastrukturą
- Wystawić endpoint
Cała logika zaimplementowana do tej pory (a więc najważniejsza logika biznesowa) jest całkowicie niezależna od użytego frameworka, sposobu łączenia się z bazą itp. Dopiero teraz nadszedł czas na połączenie z infrastrukturą. Do celów tego ćwiczenia wykorzystam flaska oraz SQLAlchemy (analogiczny przykład z Django będzie wymagał odrobinę więcej boilerplate’u i umieszczę go w osobnym wpisie).
Tak więc repozytorium:
class InsuranceRepository(Protocol):
def get(self, reference: str) -> Insurance: ...
def list(self) -> List[Insurance]: ...
def add(self, insurance: Insurance) -> None: ...
class ORMInsuranceRepository:
def __init__(self, session):
self.session = session
def get(self, identifier: str) -> Insurance:
return self.session.query(Insurance).filter_by(identifier=identifier).one()
def list(self) -> List[Insurance]:
return self.session.query(Insurance).all()
def add(self, insurance: Insurance) -> None:
self.session.add(insurance)Definicja tabel bazodanowych:
insurance = Table(
'insurance', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('identifier', String(255)),
Column('car_id', String(255)),
Column('protection_end', DateTime),
Column('status', Enum(InsuranceStatus)),
)
pause = Table(
'pause', metadata,
Column('id', Integer, primary_key=True, autoincrement=True),
Column('begin_at', DateTime),
Column('end_at', DateTime),
Column('insurance_identifier', ForeignKey('insurance.identifier')),
)
def run_mappers():
mapper(Insurance, insurance, properties={
'pauses': relationship(Pause, backref='insurance', order_by=pause.c.begin_at),
})
mapper(Pause, pause)Serwis aplikacyjny:
def resume(repo: InsuranceRepository, current_location: LocationProxy, identifier: str):
insurance = repo.get(identifier)
location = current_location(insurance.car_id)
insurance.resume(location)Oraz endpoint:
@insurance.route("/resume", methods=['POST'])
def resume_endpoint():
repo = ORMInsuranceRepository(db_session)
try:
app_services.resume(repo, current_location, request.json['identifier'])
db_session.commit()
except DomainLogicException as error:
db_session.rollback()
return response.bad_request(str(error))
except NoResultFound:
db_session.rollback()
return response.not_found()
return response.ok_no_content()W powyższym zestawieniu jedynie testy repozytorium oraz endpointu wymagają połączenia z bazą danych. Biorąc jednak pod uwagę, że zdecydowana większość logiki (a przede wszystkim cała logika stricte biznesowa) została przetestowana dokładnymi testami jednostkowymi, testy na endpoincie możemy ograniczyć do prostej weryfikacji dwóch ścieżek – pozytywnej i negatywnej.
Fragment testu repozytorium:
def test_repo_can_save_insurance(session, insurance):
repo = ORMInsuranceRepository(session)
repo.add(insurance)
session.commit()
rows = list(session.execute(
'SELECT identifier, car_id, status FROM "insurance"'
))
assert rows == [("Test", "ABC", 'ACTIVE')]Test endpointu:
def test_resume_insurance_happy_path(client, insurance, session, allowed_location):
insurance.hold()
ORMInsuranceRepository(session).add(insurance)
session.commit()
with patch('fexample.insurance.endpoints.current_location', return_value=allowed_location):
result = client.post('insurance/resume', data=json.dumps({
'identifier': insurance.identifier
}), content_type='application/json')
assert result.status_code == 204
def test_resume_insurance_unhappy_path(client, insurance, session, allowed_location):
ORMInsuranceRepository(session).add(insurance)
session.commit()
with patch('fexample.insurance.endpoints.current_location', return_value=allowed_location):
result = client.post('insurance/resume', data=json.dumps({
'identifier': insurance.identifier
}), content_type='application/json')
assert result.status_code == 400Test serwisu aplikacyjnego:
class InMemoryInsuranceRepository:
def __init__(self, insurances: List[Insurance]):
self._insurances = insurances
def get(self, identifier: str) -> Insurance:
return next(
insurance for insurance in self._insurances if insurance.identifier == identifier
)
def list(self) -> List[Insurance]:
return self._insurances
def add(self, insurance: Insurance) -> None:
if insurance in self._insurances:
self._insurances.remove(insurance)
self._insurances.append(insurance)
def test_resume_make_insurance_active(insurance, allowed_location):
insurance.hold()
repo = InMemoryInsuranceRepository([insurance])
app_services.resume(repo, lambda car_id: allowed_location, insurance.identifier)
assert repo.get(insurance.identifier).status is InsuranceStatus.ACTIVEDzięki testowej implementacji interfejsu repozytorium, test serwisu aplikacyjnego nie zależy od bazy danych
Powyższy przykład nie wyczerpuje składowych (tzw. building blocków) dostępnych w tym stylu architektonicznym. Sposób ich kompozycji czy samo zastosowanie powinno być uzależnione od konkretnego przypadku. Ten sam styl możemy aplikować w różnych odmianach, w zależności od naszych przyzwyczajeń, potrzeb (driverów architektonicznych 😉 ).
Przykład przedstawiony w tym artykule zawiera pewne uproszczenia i pomija dokładne wyjaśnienie koncepcji samego stylu architektonicznego, jego mocnych i słabych stron oraz cały proces myślowy stojący za tworzeniem poszczególnych elementów rozwiązania. Zaprezentowałem go tutaj, chcąc na konkretnym kodzie pokazać istnienie różnic w podejściach do modelowania aplikacji oraz dać głębsze odczucie ich konsekwencji. Ponieważ zarówno temat architektury oprogramowania jak również kwestia praktycznej implementacji różnych wzorców w Pythonowym sosie są bardzo szerokie, będziemy powracać do nich w kolejnych artykułach.
Dajcie znać co sądzicie o temacie architektury oprogramowania w kontekście Pythona i jak to wygląda u Was w projektach 🙂 Do niebawem, cześć!
PS: Repozytorium z kompletnym przykładem we Flasku i odpowiednikiem w Django znajdziecie tutaj: https://github.com/mikolevy/python-architecture-examples
Cześć, dzięki za analize, dobry artykuł. Spotkałam sie zarówno z pierwszym jak i drugim podejściem, dużo zależało od przeznaczenia serwisu. Serwis z konfiguracjami opierał się o zwykłe crudy, natomiast serwisy z akcjami biznesowymi miały bardziej zdefinowane przeznaczenie, na przykład uruchom proces. Chociaż zdecydowanie wole drugie podejście, pozwala na większą elastyczność przez dodatkową warstwe abstrakcji.