
Jakiś czas temu w ręce (a dokładniej na skrzynkę mailową) wpadło mi nagranie pochodzące z konferencji PyCon Cleveland, która odbyła się na początku maja. Jak na porządną konferencję przystało, wszystkie nagrania są dostępne w sieci (można je znaleźć np. na youtube) więc nawet jeżeli nie mieliśmy w tym roku szansy odwiedzić Cleveland część merytoryczną możemy nadrobić w domu ;). Jeden z filmików to 30 minutowe wystąpienie Anthony’ego Shaw’a. Opowiada on jak mierzyć i ograniczać złożoność w naszych programach. Prezentacja dotyczy również programu Wily, którego Anthony jest głównym twórcą i pomysłodawcą.
Wily to program open-source, który pozwala wyznaczyć wartości kilku metryk jakościowych dla wybranych plików. Metryki te możemy obliczyć dla kolejnych rewizji w repozytorium, a następnie obejrzeć wyniki w postaci wykresu lub tabelki generowanej w konsoli. Pozwala to przeanalizować jakość każdego z plików oraz historię jej zmiany w czasie.
W domyślnej konfiguracji liczone są 4 metryki:
– Liczba unikalnych operandów (zmiennych i wartości)
– Liczba linii kodu (LOC)
– Złożoność cyklomatyczna (CC)
– Maintainability Index (MI)
Zaglądając w kod Wily’ego zobaczymy, że integruje on kilka bibliotek, które liczą metryki, obsługują przełączanie pomiędzy rewizjami i rysowanie wykresów (radon, plotly). Z perspektywy użytkownika dostajemy przyjemny, prosty interfejs konsolowym.

Widząc możliwości tego narzędzia zacząłem zastanawiać się czy można za jego pomocą w efektywny i prosty sposób zmierzyć dług techniczny aplikacji? Czy pozyskana w ten sposób informacja mogłaby przydać się podczas rozwijania nowego systemu oraz estymacji kosztów utrzymania już istniejącego?
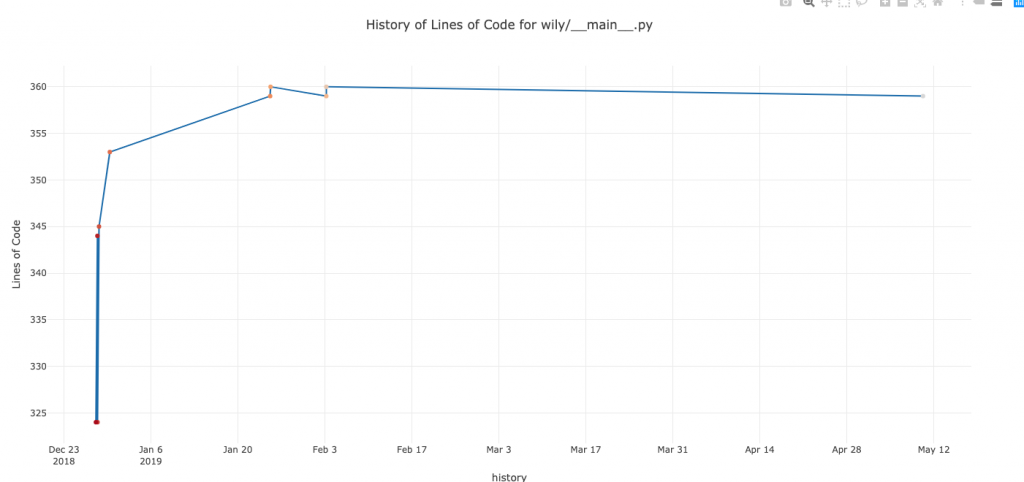
Analiza metryki – liczba linii kodu
Zacznijmy od liczby linii kodu. Co wartość ta mówi nam o danym pliku? Cóż… jeżeli jest duża to zapewne dużo się w nim dzieje :). Z jednej strony taki plik może nam bardzo dużo powiedzieć o systemie, gdyż najpewniej znajdują się w nim najbardziej skomplikowane (i często najważniejsze biznesowo) elementy aplikacji. Z drugiej strony kumulacja odpowiedzialności w jednym pliku zazwyczaj będzie wskazywać na naruszenie Single Responsibility Principle.
Ok – ale co to znaczy „dużo” linii kodu? I kiedy powinniśmy stwierdzić, że jest ich „za dużo”? To zależy.
– Po pierwsze od technologii. W językach bardziej opisowych do obsłużenia tej samej ilości logiki biznesowej będziemy musieli więcej się naklepać. 50 linii w Pythonie może „przetłumaczyć się” na 150 linii w C, więc naturalnie programista C będzie pisał dłuższe programy.
– Po drugie od tego co robi dany kod. Czym innym jest 100 linii kodu z deklaracjami mapowania klas na tabele w bazie danych, a czym innym 100 linii logiki wyznaczania rabatów i dostępności towarów.
– Po trzecie ważny jest również czynnik ludzki. Dla jednego dwustulinijkowiec w Pythonie jest całkowicie w porządku, ktoś inny może być zdegustowany. Te różnice biorą się z subiektywnego poczucia estetyki, z innego postrzegania i rozumienia tego czym jest dany program komputerowy oraz tego jak dana osoba modeluje go sobie w głowie.
Warto w tym momencie zastanowić się nad kwestią z pozoru dość oczywistą – dlaczego w ogóle kod może być za długi? Otóż problemem nie jest sam rozmiar pliku ale ilość logiki, która jest w nim zawarta. Nasze mózgi po prostu nie radzą sobie zbyt dobrze z dużym nagromadzeniem możliwych opcji i skomplikowanych warunków. To dlatego potrzebujemy kolejnych warstw abstrakcji, aby nie pogubić się w tym wszystkim.
Zapewne łatwo możemy stwierdzić, że plik zawierający 5000 linii będzie problematyczny (nawet scroll z góry na dół zajmie nam trochę 😉 ) ale niestety na tym koniec łatwych odpowiedzi. Bo nie da się wprost stwierdzić, że 600 linii jest 2 razy trudniejsze do zrozumienia, ani nawet 2 razy bardziej złożone niż 300. Po więcej informacji musimy pochylić się nad konkretnym przypadkiem, otworzyć plik i zajrzeć do środka.
Samemu zdarzyło mi się stosować metrykę LOC jako wsparcie na początku ogólnej analizy systemu. Zazwyczaj miało to miejsce w sytuacji, kiedy nie miałem możliwości kontaktu z osobami zaangażowanymi w jego powstawanie. Pierwszą przesłanką na temat stanu aplikacji jest dla mnie istnienie tzw. ośmiotysięczników 😉 Ich brak nie gwarantuje nam świetnej jakości ale obecność tak długich plików nie zwiastuje niczego dobrego. Drugi wniosek, który można wyciągnąć patrząc na samą liczbę linii kodu, to odpowiedź na pytanie, od których plików rozpocząć analizę systemu. Wiadomo, to oczywiście zależy – jaki jest to system, do czego służy, jaką posiada architekturę itp. Ale w sytuacji gdy nie posiadamy tych informacji, możemy rozpocząć od ogólnego przejrzenia plików najdłuższych i najpewniej skrywających najwięcej ciekawostek 😉 .
Złożoność cyklomatyczna
Złożoność cyklomatyczna (CC) wyrażana jest przez liczbę miejsc „decyzyjnych” w naszym programie. Tak więc każdy if, każdy try/except, każda pętla – podbije tę wartość. Brzmi to dość sensownie. Łatwo się zgodzić, że wraz ze wzrostem zagmatwania ifologii czytelność kodu drastycznie spada. Ograniczając CC poszczególnych funkcji czy metod, powinniśmy uzyskać w miarę proste i przejrzyste implementacje, możliwe do ogarnięcia przez statycznego programistę bez potrzeby sięgania po chemiczne wspomagacze. Spotkałem się z opiniami, że właśnie za pomocą tej metryki dobrze jest mierzyć dług techniczny oprogramowania. Oczywiście znowu możemy zadać trudne pytanie o graniczne wartości tego co znaczy „dobrze”. Podobnie jak w przypadku analizowania długości pliku, odpowiedź nie będzie jednoznaczna.
Złożoność cyklomatyczna jest jednak metryką, która w pewien sposób próbuje abstrahować od technologii i reprezentować rzeczywistą porcję logiki zawartą w programie. W związku z tym możemy uznać wnioski wyciągnięte na jej podstawie za bardziej uniwersalne, a wartości łatwiejsze do porównania pomiędzy projektami niż w podczas liczenia linii kodu. Co ciekawe, aplikując CC nie na konkretnych funkcjach czy metodach ale na całym procesie biznesowym, moglibyśmy podjąć próbę oszacowania jego złożoności. W tym miejscu warto przypomnieć o tym, że w przypadku procesu, złożony nie znaczy zły. Czym innym jest zagmatwana funkcja, którą powinniśmy podzielić na mniejsze, a czym innym skomplikowany proces biznesowy. Procesy biznesowe są złożone – taki ich urok. To właśnie implementacja nietrywialnych rozwiązań stanowi ciekawe wyzwanie i pozwala zastosować zaawansowane techniki modelowania dając przy tym dużo satysfakcji. W tym kontekście ważne jest to jak zaprojektujemy system wspierający tego rodzaju procesy. Jakie wprowadzimy abstrakcje, interfejsy, jak podzielimy odpowiedzialność pomiędzy moduły. Będzie to miało bezpośredni wpływ na to, ile w ostatecznym programie pojawi się złożoności esencjonalnej (wynikającej z problemu), a ile przypadkowej (wynikającej z naszej nie do końca udanej „walki” ze złożonością esencjonalną).
Maintainability Index
Czyli to, co tygryski lubią najbardziej. Wzór, wynik, przedziały interpretacji. Faktem jest, że wzór i przedziały różnią się w zależności od wariantu ale w ogólności mamy (dociekliwi dokładniejszej definicji poszczególnych składowych wzoru znajdą ją filmiku Anthon’ego):
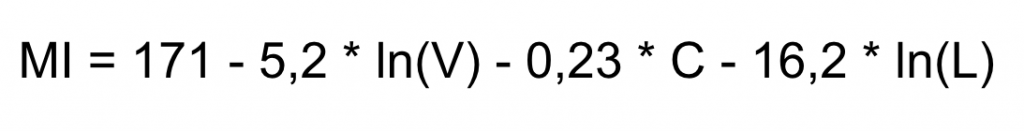

Aby wyznaczyć MI dla wybranego pliku musimy obliczyć poszczególne wartości i podstawić je do wzoru. Oczywiście nie trzeba robić tego na piechotę – we wszystkim wyręczy nas Wily. Uzyskany wynik klasyfikujemy do jednego z czterech przedziałów i już wiemy czy z tym kawałkiem kodu da się jeszcze żyć czy może trzeba go zaorać 😉 Wyciąganie wniosków o jakości kodu na podstawie MI jest kusząco proste, choć z drugiej strony formuła przedstawiona w takiej podstaci może wydawać się trochę niewiarygodna. Pierwsze pytanie które nasuwa się na myśl to „skąd wzięło się tam 171?”
Wzór na MI wyznaczony został w sposób empiryczny. Jego twórcy poprosili grupę inżynierów o dokonanie subiektywnej oceny jakości kodu (a dokładniej jego utrzymywalności) i przyznanie mu oceny w skali od 1 do 100. Dla tych samych systemów obliczyli również wartości kilkudziesięciu metryk. Następnie stosując techniki statystyczne znaleźli taki zestaw metryk i współczynników, którego wskazania najlepiej odpowiadały ocenom przyznanym przez ludzi. Ciekawy post na temat MI napisał na swoim blogu Arie van Dursen. Powątpiewa on w rzeczywistą przydatność tej „magicznej” formuły. Poszukując naukowych podstaw stosowania tego typu metryk warto sięgnąć również do cytowanych przez niego badań.
MI nie jest najnowszym odkryciem. Wzór ma już ponad 20 lat i trochę się od tego czasu pozmieniało. Pytanie, czy w nowej rzeczywistości formuła nadal działa? Pierwotnie wzór został wyznaczony w sposób empiryczny z udziałem inżynierów – ekspertów. Postanowiłem przeprowadzić podobny eksperyment. Zapytałem kilku znajomych programistów i programistek o ich odczucia na temat jakości kodu. Pytanie dotyczyło 4 plików pochodzących z projektów, które znają. Po zebraniu wyników zestawiłem je z wartościami MI wyliczonymi z użyciem Wily’ego.
Oczywiście nie jest to żadne wielkie badanie naukowe, gdyż zarówno próba jak i sposób jego przeprowadzenia były mocno ograniczone możliwościami czasowymi. Wyniki można jednak potraktować jako ciekawostkę. Nie zawsze MI pokrywa się z odczuciami ankietowanych, aczkolwiek wartości te są raczej zbliżone.
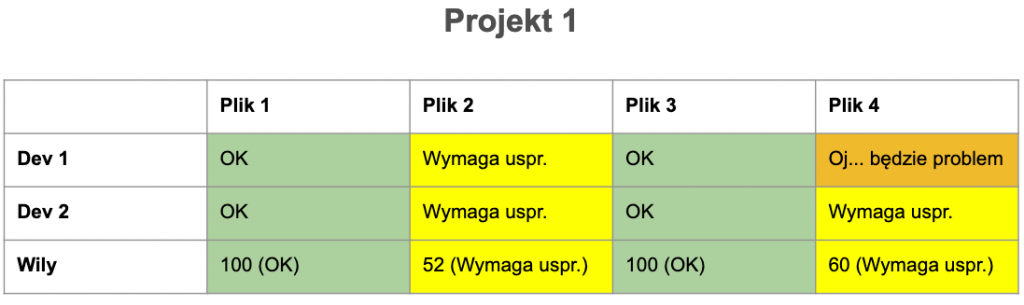
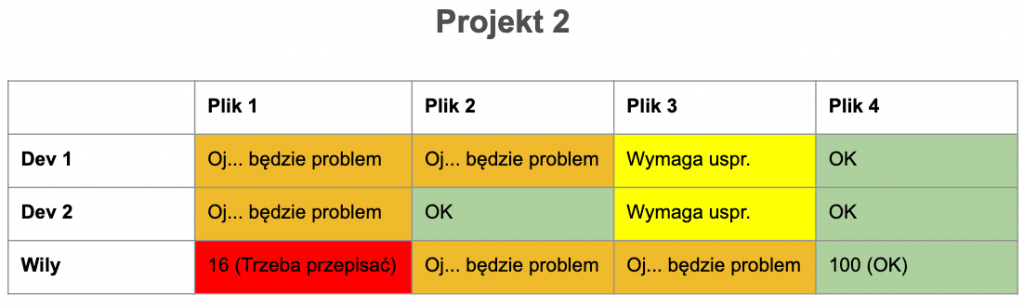
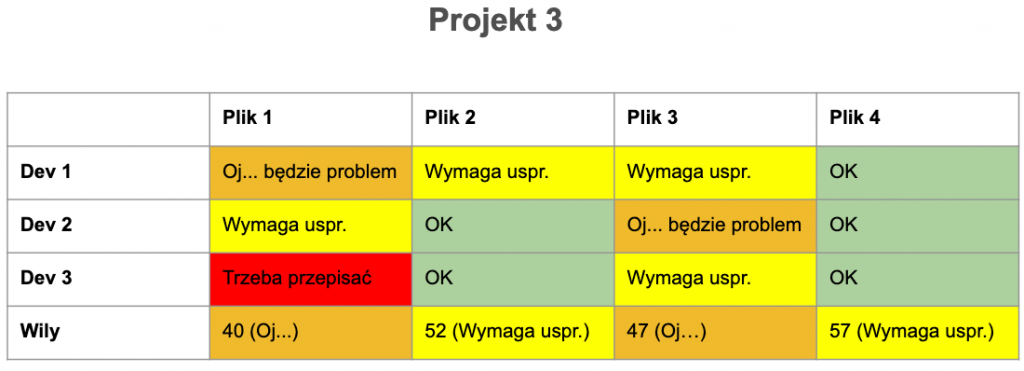
Liczyć czy nie liczyć?
Osobiście zawsze miałem dość sceptyczne podejście do różnego rodzaju magicznych wzorów, które w uniwersalny sposób mierzą dług techniczny, czy jakość oprogramowania. Bo jak można jedną miarą ocenić program nie biorąc pod uwagę tego czy jest on napisany w Javie, C, Pythonie czy Perlu? Niezależnie od tego jaką ma architekturę, jakie wykorzystuje paradygmaty czy frameworki? Niezależnie od tego jaki jest CEL istnienia tego oprogramowania?
W tym kontekście interesujące mogą być nie tyle same wyniki „eksperymentu” co czas poświęcony na dokonanie oceny. Dla każdego z plików wystarczyło dosłownie kilka minut. Czy jest w takim wypadku sens liczenia tego typu metryki skoro o analogiczną ocenę można po prostu zapytać programistów? Nie chciałbym odrzucać takiego podejścia ale osobiście uważam, że szczera rozmowa z twórcami aplikacji będzie lepszym rozwiązaniem.
Może MI przydałby się w sytuacji, w której nie mamy dostępu do nikogo kto zna projekt a chcemy szybko rozeznać się w ogólnym stanie systemu? Np. na potrzeby jakiejś estymaty? Tutaj widzę pewien potencjał, chociaż sporym wyzwaniem będzie przeniesienie ocen z poszczególnych plików na całą aplikację. Na tak ogólnym poziomie istnieje również kilka konkurencyjnych metryk/informacji, np: pokrycie testami, istnienie testów akceptacyjnych, poziom automatyzacji dotychczasowego developmentu. A może dobrym zastosowaniem MI jest wykorzystanie go jako sposóbu na zagwarantowanie jakości kodu w projekcie? Np. poprzez failowanie builda za każdym razem, gdy liczona na CI wartość spadnie poniżej oczekiwań?
Podczas dyskusji na ten temat, jedna z osób zwróciła uwagę na narzędzia i techniki, które już stosujemy. Obecnie w wielu firmach standardem jest wykorzystanie linterów, odpalanie testów jednostkowych i e2e, wymaganie odpowiedniego pokrycia oraz type checking. Teoretycznie, wszystkie te „sprawdzacze” da się oszukać. Oczywiście w sposób nieświadomy (zakładam, że każdy się stara zrobić swoją robotę dobrze). Może się zdarzyć, że nieumiejętnie napisane testy nic nie testują i tylko podbijają coverage. Trafiają się przecież systemy ze stosunkowo wysokim pokryciem, a mimo wszystko dość ciężkie w utrzymaniu. Jednak w tej nierównej walce, przeciw bugom i kaskadom ifów, mamy do dyspozycji jeszcze jedną broń. Code review. Rzetelnie wykonane powinno zagwarantować jakość i czytelność kodu ocenioną z perspektywy innego programisty. Czy w związku z tym potrzebujemy czegoś jeszcze? Może wystarczy dobrze wykorzystać zestaw tych narzędzi, których już używamy? I przede wszystkim zadbać o dobre i porządne przeglądy kodu? Myślę, że na ostatnie pytanie odpowiedź może być tylko jedna 😉
Bardzo jestem ciekawy jak wygląda to w Waszych projektach? Czy znacie/stosujecie jakieś magiczne metryki? Dajcie znać w komentarzu! Do napisania, hej!
Hej, ciekawy eksperyment. Nigdy nie miałam okazji estymować całego projektu ale estymując większe lub mniejsze zadania ważnymi kryteriami są dla mnie złożoność problemu i pokrycie testami. Z mojej perspektywy testowalność kodu zwykle dużo mówi o jego jakości, ich brak, najczęściej, oznacza konieczność przebudowania klas – doprowadzenia ich do stanu testowalnego oraz nadrobienia braków. Zwiększa to też ryzyko i zdecydowanie zmniejsza komfort pracy, co też wydłuża czas do zakończenia zadania. Mhm. Testy są dla mnie najważniejsze.